|
High Performance Networking
Hardware Design Department of Electrical and
Computer Engineering Northwestern University |
Introduction
Processor designers have traditionally dealt with compromises
between performance increase, energy reduction, increased reliability, and/or
increase in design complexity. However, one important aspect that was omitted
is the correctness. The traditional approach in processor design has been:
“regardless of the properties of a processor/system, it must be 100% correct”.
In other words, when an application is executed, the output has to be always
according to the program semantics. In this project, we will question this
traditional approach and argue the importance of correctness in the context of
networking hardware.
In many application domains, hardware faults cannot
be tolerated, e.g., most server applications require high levels of
reliability. However, some applications are immune to a certain level of faults
in the system. For example, in networking applications, if a small fraction of
the packets are handled incorrectly, the integrity of the system’s behavior can
still be maintained. Since network processors are designed for a particular
application domain, it seems natural to take advantage of this robustness. We
aim to achieve this with the design of clumsy packet processors,
which utilize “fault throttling” techniques to increase their performance
and/or energy efficiency while increasing the probability of hardware faults.
We have shown that one can trade-off a small increase in the fallibility of a
processor (less than 1 in 100,000 iterations) while achieving significant
improvements in performance or energy efficiency (2 to 4 times). To measure the
impact of a fault, we embark on two research questions. First, how can we
measure the importance of a change in the output of an application? Second, how
do faults of a hardware component impact the output behavior of the
application? To answer the first question, we design a library where the user
can tell the importance of a data element. For the second, we implement a
processor simulation framework that models certain circuit-level events.
Another research aspect we will study is new fault throttling techniques.
Overview
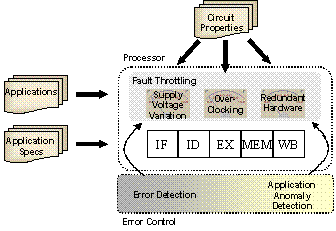

Figure 1. Overview of the approach.
The system
architecture overview and some of the research directions in this work are
presented in Figure 1. In this system, the processor “throttles” the expected fault
rates of different processor components according to the application
specifications. This throttling can be done statically (particularly if the
network processor is designed for a known set of applications, off-line
analysis can extract the optimal operation configuration in the processor) or
dynamically. There are several variations of the dynamic throttling processors.
The simplest one is named clumsy packet processor, where the processor assumes
certain fault models for components and does not perform any fault detection.
In this case, the application specification indicates the error rates it can
tolerate and the processor selects the configuration according to the fault
models established off-line. A second variation of the approach is to implement
error control schemes while dynamically throttling the fault rates. In this
method, the additional error control schemes (e.g., error correction and
detection schemes such as ECC) have energy and/or performance bottlenecks.
Hence, we need to perform a detailed energy-performance-reliability trade-off
for each possible optimization. As part of this variation, we will also develop
efficient network-specific reliability measures.
People
Faculty
Prof. Gokhan Memik
Graduate Students
Arindam Mallik
Undergraduate
Students
Steve Lieberman
Matthew C. Wildrick
Publications
Refereed Journal
Papers
Application-Level
Error Measurements for Network Processors
Arindam
Mallik, Matthew C. Wildrick, Gokhan Memik
To
appear in IEICE Transactions on Information and Systems
Refereed Conference
Papers
Engineering Over-Clocking:
Reliability-Performance Trade-Offs for High-Performance Register Files
Gokhan Memik, Masud H. Chowdhury,
Arindam Mallik, Yehea I. Ismail
International Conference on Dependable
Systems and Network (DSN-05), Yokohama,/Japan, June, 2005
A Case for Clumsy Packet Processors
Arindam Mallik and Gokhan Memik
International Symposium on Microarchitecture
(MICRO'37), Portland/OR,
Dec. 2004
Measuring Application Error Rates for Network
Processors
Arindam Mallik, Matthew C. Wildrick, Gokhan Memik
IEEE International Midwest Symposium on Circuits and
Systems (MWSCAS), Hiroshima/Japan, July 2004 (invited paper)
Sponsored by:
|
|
Department of Energy, Mathematical, Information
and Computational Sciences Early Career Award #DE-FG02-05ER25691. |
