We have implemented the cube construction and scheduling algorithms on a shared nothing parallel computer, the IBM-SP2. Each node is a 120MHz PowerPC, has 128MB memory and a 1GB of available diskspace. Communication between processors is through message-passing and is done over a high performance switch, using Message Passing Interface (MPI).
Our first prototype implementation was using multidimensional arrays for up to 10 dimensions, using 1D partitioning for complete datacube construction showing good parallel performance for the various stages involved. Figure 4 shows a sample result on a OLAP council benchmark. We are currently implementing a scalable multidimensional engine capable of handling large datasets, high number of dimensions, using chunks and sparse data structure (BESS) suitable for dimensional analysis. This supports both 1D and 2D partitioning, dense and sparse chunks, the various scheduling alternatives and optimizations.
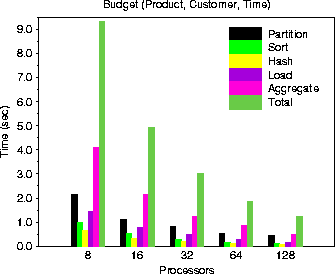
Figure: Various phases of cube construction using sort-based method for Budget data
(from OLAP council benchmark) (N = 951,720 records, p = 8, 16, 32, 64 and 128 and data size = 420MB)
Assuming initial data from a relational database, the following summarizes the steps in the overall process. Assume N tuples and p processors.
Four data sets, one each of 5D, 10D and two of 20D are considered. Table
1 describes the four datasets. The products of their
dimensions are ![]() and
and ![]() respectively. Different
densities are used to generate uniformly random data for each data set
to illustrate the performance. A maximum of nearly 3.5 million tuples
on 8 and 16 processors is used for the 20D case.
respectively. Different
densities are used to generate uniformly random data for each data set
to illustrate the performance. A maximum of nearly 3.5 million tuples
on 8 and 16 processors is used for the 20D case.

Table 1: Description of datasets and attributes, (N) Numeric (S) String
Results are presented for partitioning, sorting and chunk loading steps in Figure 5 and Figure 6. These show good performance of our techniques and show that they provide good performance on large data sets and are scalable to larger data sets (larger N) and larger number of processors (larger p). Even with around 3.5 million tuples for the 20D set, the density of data is very small. We are using minichunk sizes of 25 BESS-value pairs. With this choice, the data sets used here run in memory and the chunks do not have to be written and read from disk. However, with greater densities, the minichunk size needs to be selected keeping in mind the trade-offs of number of minichunks in memory and the disk I/O activity needed for writing minichunks to disk when they get full. Multiple cubes of varying dimensions are maintained during the partial data cube construction. Optimizations for chunk management are necessary to maximize overlap and reduce the I/O overhead. We are currently investigating disk I/O optimizations in terms of the tunable parameters of chunk size, number of chunks and data layout on disk with our parallel framework.
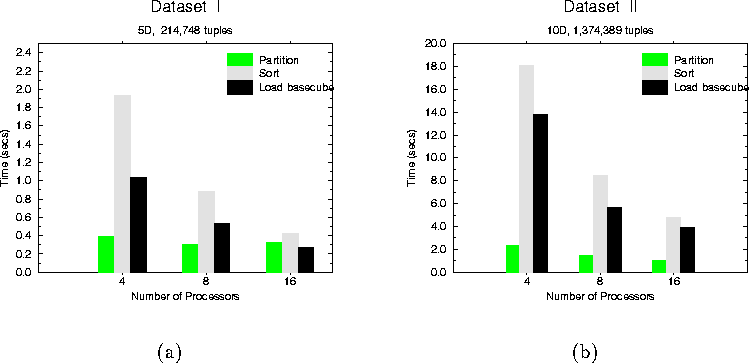
Figure 5: (a) Dataset I (5D, 214,748 tuples) (b) Dataset II (10D, 1,374,389 tuples)
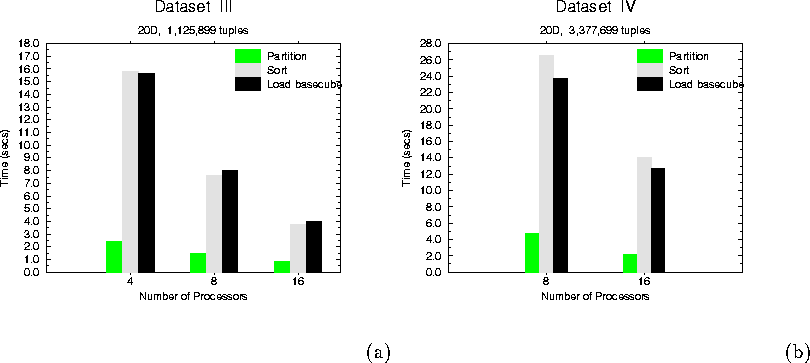
Figure 6: (a) Dataset III (20D, 1,125,899 tuples) (b) Dataset IV (20D, 3,377,699 tuples)