Data is distributed on processors to distribute work equitably. In
addition, a partitioning scheme for multidimensional has to be
dimension-aware and for dimension-oriented operations have some
regularity in the distribution. A dimension, or a combination of
dimensions can be distributed. In order to achieve sufficient
parallelism, it would be required that the product of cardinalities of
the distributed dimensions be much larger than the number of
processors. For example, for 5 dimensional data (ABCDE), a 1D
distribution will partition A and a 2D distribution will partition
AB. We assume, that dimensions are available that have cardinalities
much greater than the number of processors in both cases. That is,
either ![]() for some i, or
for some i, or ![]() for some i,
j,
for some i,
j, ![]() , n is the number of dimensions.
Partitioning determines the communication requirements for
data movement in the intermediate aggregate calculations in the data cube.
Figure 2 illustrates 1D and 2D
partitions on a 3-dimensional data set on 4 processors.
, n is the number of dimensions.
Partitioning determines the communication requirements for
data movement in the intermediate aggregate calculations in the data cube.
Figure 2 illustrates 1D and 2D
partitions on a 3-dimensional data set on 4 processors.
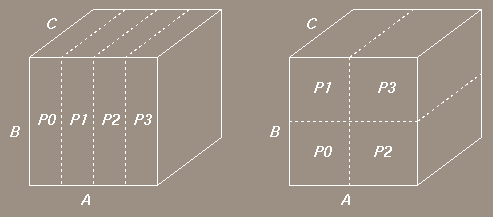
Figure 2: 1D and 2D partition for 3 dimensions on 4 processors